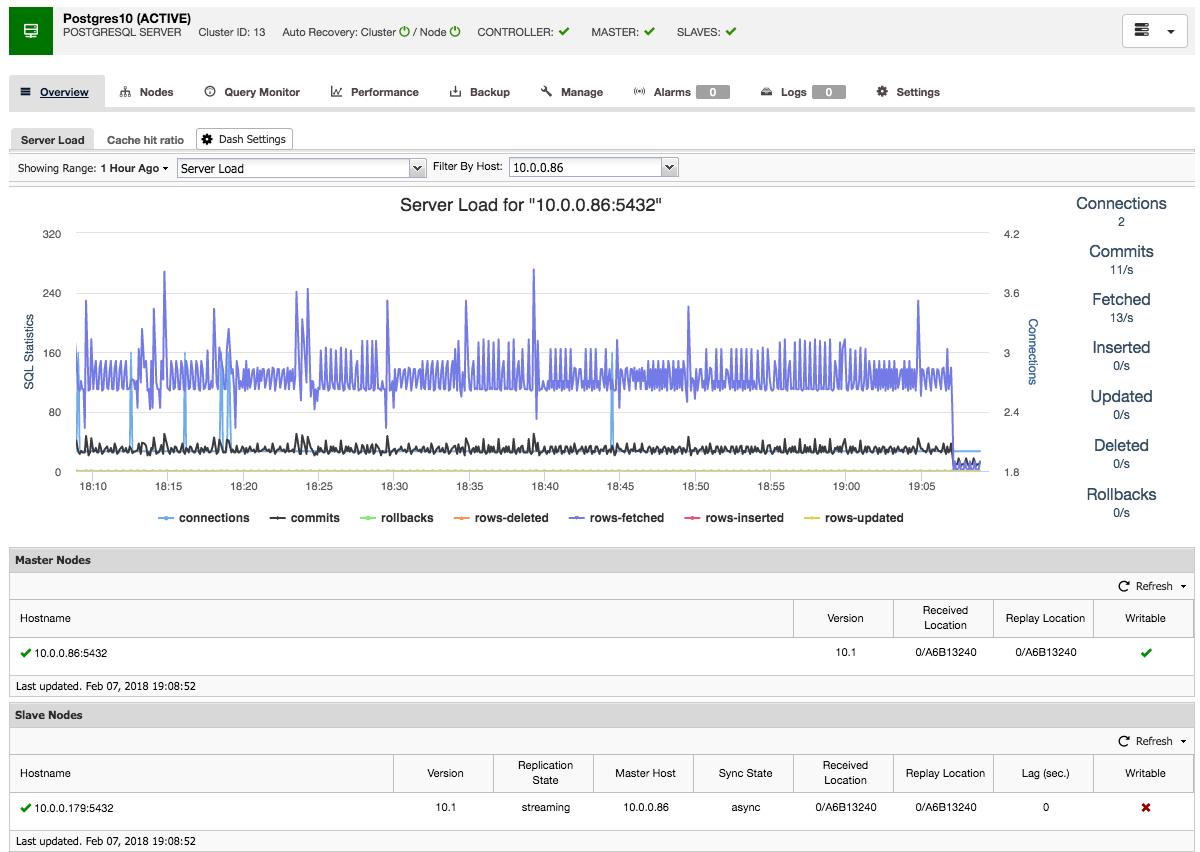
PostgreSQL server configuration parameters play an important role in optimizing and enhancing database performance.
Usually in any environment, default parameters are not enough, and this is where an understanding of important server parameters can contribute greatly to influence database performance. Understanding these can be critical to reducing server downtime just for routine configuration changes, as well as making sure you're adjusting the parameter you want at the time when you want the change to take effect.
The main tunable settings for PostgreSQL are in a plain text file named postgresql.conf, that is located at the base of the database directory structure.
The majority of these configuration parameters are broadly classified under the following categories:
- Database Connection Parameters
- Logging Parameters
- Memory Parameters
- WAL Parameters
- Query Tuning Parameters
Most of these parameters can be changed by making the respective changes in the postgresql.conf file manually. A convenient way is to do the changes using ClusterControl. It allows to make the required configuration changes from the web interface, allowing for more fine grained control and without the need for the end user to locate and poke directly in the postgresql.conf file on the backend.
In this blog, we focus on connection, logging and memory parameters. The other categories are mostly from a system/query tuning perspective, we will look at these in subsequent blogs.
Connection Parameters
There are many configuration parameters that control how people can connect remotely and locally to the database.
listen_addresses
Any installation that requires a connection from a remote system will need to change listen_addresses to allow that. The default only allows local connections from users logged into the same system as the database server. A common approach is to accept incoming connections from anywhere-as far as the primary configuration file is concerned like this:
listen_addresses = '*'max_connections
Max_connections is one of the settings that you'll always find set to a value, typically 100, in the postgresql.conf generated by initdb. Because each connection uses a small amount of shared memory, it's possible for systems with particularly limited shared memory defaults to not even allow this many connections. Accordingly, some investigation is done by initdb when the database cluster is created, and then the largest value supported - up to 100 - is saved into the default configuration. In practice, the amount of non-shared memory each client uses for things such as sorting will dwarf this, but the shared component cannot be completely ignored.
It is important not to set this parameter to a value much higher than you need it to be. There are several downsides to larger settings. The first is wasted shared memory, typically the last of the things to be concerned about as the amount per connection is small.
Logging Parameters
The general logging setup is vital and important as logging can play a crucial role in debugging error, warning and other system issues. You may need to set parameters such as log_destination, log_directory, and log_filename to save your log files in a way that is compatible with the system administration requirements of your environment. On most systems these will all be set to reasonable defaults to get started. On UNIX-like systems, it's common for some of the database logging to be set in the script that starts and stops the server, rather than directly in the postgresql.conf file.
log_line_prefix
The default log_line_prefix parameter is empty, which is not what you want. A good starting value here is the following:
log_line_prefix='%t:%r:%u@%d:[%p]: 'This will put the following into every log line:
%t: Timestamp
%u: Database username
%r: Remote host connection
%d: Database
%p: Process ID of connection
It may not be immediately obvious what you'd want all of these values for, particularly the process ID. Once you've tried to chase down a few performance issues, the need for saving these values will be more obvious, and you'll be glad to already have this data logged.
log_statement
Statement logging is a powerful technique for finding performance issues. Analyzing the information saved by log_statement and related sources for statement-level detail can reveal the true source of many types of performance issues.
The options for this setting are as follows:
none: Do not log any statement-level information.
ddl: Log only data definition language (DDL) statements such as CREATE and DROP. This can normally be left in, even in production, and can be used to catch major changes introduced accidentally or intentionally by administrators.
mod: Log any statement that modifies a value, which is essentially everything except for simple SELECT statements. If your workload is mostly SELECT-based with relatively few data changes, it may be practical to leave this enabled all the time.
all: Log every statement. This is generally impractical to leave on in production due to the overhead of the logging. However, if your server is powerful enough relative to its workload, it may be practical to keep it on all the time.
log_min_duration_statement
Once you have some idea of how long a typical query statement should take to execute, this setting allows you to log only the ones that exceed the threshold you set. The value is in milliseconds, so you might set the following:
log_min_duration_statement=1000With this, you'll only see statements that take longer than 1 second to run. This can be extremely handy for finding out the source of outlier statements that take much longer than most to execute.
Memory Parameters
Database components require memory for caching frequently accessed data, transaction logging and for sorting data. Hence it is critical that memory parameters be tuned correctly as it can help optimize database performance.
shared_buffers
The value of this parameter defines the size of the PostgreSQL shared buffer pool. In other words, this parameter governs the amount of memory to be used by PostgreSQL for caching data. The default value of 128 MB is quite low for any real world workload and needs to be beefed up. This value should be set based on the dataset size, which the database server is supposed to handle at peak loads and on the basis of the available RAM. The defacto rule of thumb is that, on systems with more than 1GB of RAM, a reasonable value for this parameter would be around one fourth of the system memory. The value of this parameter can also be set to a larger value and will be ideally effective up to a maximum setting of 40% of the available RAM. But increasing it beyond that limit may not be effective because PostgreSQL also relies on the operating system cache as well for its operations. A large value for the shared_buffers parameter would mean an increase in the checkpoint_segments value, in order to spread out the process of writing large quantities of new or changed data over a period of time.This value can only be set at server start.
temp_buffers
This parameter defines the amount of memory to be used by each database session for caching temporary table data. These are basically session local buffers, used only for access to temporary tables. The default value of this parameter is eight in Postgresql version 9.4, and this setting can be changed within individual sessions but only before the first use of temporary tables within the session. Any subsequent attempts to change the value will have no effect on the existing session.
maintenance_work_mem
This parameter defines the maximum amount of memory to be used by maintenance operations, i.e., VACUUM , CREATE INDEX, ALTER TABLE ADD FOREIGN KEY operations which need more working memory. The catch is that it is unlikely to be seen that many of these sessions will be doing these operations at the same time, so it is possible to set this value to a much larger value than the standard per client work_mem setting. The default value of this parameter is set to 64MB in PostgreSQL version 9.4. One thing to be noted here is that, when autovacuum runs, a value of autovacuum_max_workers times this memory gets allocated. From the point of optimization and considering that one has not increased the number of autovacuum workers, a good configuration setting would be to set this to around 5 % of the total system memory so that even five such processes would not exceed a quarter of the available memory. This approximately works out to 50 MB of maintenance_work_mem per GB of the server's system memory.